BOM(Byte order Mark)是Unicode规范中推荐的标记字节顺序的方法。
在UCS 编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输 字符”ZERO WIDTH NO-BREAK SPACE”。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF(读者可以用我们前面介绍的编码方法验证一下)。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
在UCS 编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输 字符”ZERO WIDTH NO-BREAK SPACE”。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF(读者可以用我们前面介绍的编码方法验证一下)。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
08-01
22
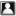 Illegal mix of collations (utf8_bin,IMPLICIT) and (latin1_swedish_ci,COERCIBLE)
Illegal mix of collations (utf8_bin,IMPLICIT) and (latin1_swedish_ci,COERCIBLE)
作者:Java伴侣 日期:2008-01-22
错误如下:
 引用内容
引用内容
编码问题,一个表是latin1字符集的,而传进的参数是UTF-8的,所以需要统一字符集,指令如下:
引用内容General error, message from server: "Illegal mix of collations (latin1_swedish_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE) for operation 'like'"
编码问题,一个表是latin1字符集的,而传进的参数是UTF-8的,所以需要统一字符集,指令如下:
复制内容到剪贴板 程序代码
程序代码
程序代码mysql> Alter TABLE suggest CONVERT TO CHARACTER SET utf8;
Query OK, 98 rows affected (0.05 sec)
Records: 98 Duplicates: 0 Warnings: 0
Query OK, 98 rows affected (0.05 sec)
Records: 98 Duplicates: 0 Warnings: 0

