 程序代码
程序代码<iframe ID="Editor" name="Editor" src="路径/ubb/edit.htm?id=content" frameBorder="0" marginHeight="0" marginWidth="0" scrolling="No" style="height:320;width:100%"></iframe>
编辑内容时调用编辑器方法:
程序代码<iframe ID="Editor" name="Editor" src="路径/ubb/edit.htm?id=content" frameBorder="0" marginHeight="0" marginWidth="0" scrolling="No" style="height:320;width:100%"></iframe>
显示数据库的内容方法:
今天往系统里面加UBB,如图:
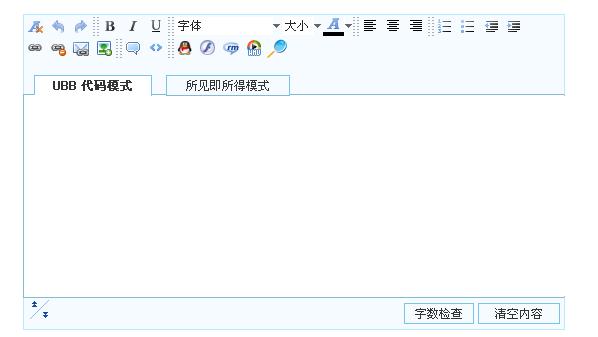
这个源码是我从ASP系统上面扒下来的,感觉挺不错,JS中正则写得很全.期间遇见的两个问题,一处Images和Js大写都不认,再来此代码是在gb2312下用的,所以需要用记事本重新保存所有执行文本. 总得来说并不难
Tags: UBB
首先遇到的是界面问题,实际上这个很好解决,只是利用td的onmouseover、onmouseout和onmousedown来实现,具体实现方法件下面的代码。
其次就是实现文本效果的问题,这个可以利用textRange的execCommand方法来实现。
下面我给出一个简单的例子,你可以把它存为一个html文件,直接可以运行,这个例子的功能很简单,就是把编辑框中选定的文字变为粗体或斜体。其他功能你可以参照这个例子自己加上。
对了,先把这两个图片存下来。
file : ubb.html
程序代码 相信大家一定可以想到UBB代码的解析,其实就是将“[b][/b]”这样的格式转换成““”就可以了,但是怎么转换呢?答案是用正则表达式。利用上一期讲到的正则表达式类(sony.utils.Regex)中的eregi_replace替换方法,可以很轻松地做到。下面是一段示例。
String s="[b]这是粗体[/b]";
String result;
result = Regex.eregi_replace("[b](.+?)[/b]","“$1“", s);
System.out.println(result);
//打印结果是:
//“这是粗体“。
这么简单吗?是的,我们只需要将其它的UBB Tag作类似的替换就实现了UBB代码的解析了。
下面给出一个UBB类.
/***************************UbbCode.java****************************************/
import java.util.regex.Matcher; //导入所需要的类
import java.util.regex.Pattern;
public class UbbCode //类定义
{
private String source; //待转化的HTML代码字符串
private String ubbTags[]; //UBB标记数组
private String htmlTags[]; //HTML标记数组
//初始化,分别为UBB标记数组和HTML标记数组赋值
public UbbCode()
{
byte byte0 = 74;
source = new String();
ubbTags = new String[byte0];
htmlTags = new String[byte0];
ubbTags[0] = "[b]";
htmlTags[0] = "<b>";
ubbTags[1] = "[/b]";
htmlTags[1] = "</b>";
ubbTags[2] = "[i]";
htmlTags[2] = "<em>";
ubbTags[3] = "[/i]";
htmlTags[3] = "</em>";
ubbTags[4] = "[quote]";
htmlTags[4] = "<div style=\"border-style:dashed;background-color:#CCCCCC;border-width:thin;border-color:#999999\"><br><em>";
ubbTags[5] = "[/quote]";
htmlTags[5] = "</em><br><br></div>";
ubbTags[6] = "[/size]";
Tags: UBB
package order.bean.ubb;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Util {
public static String clearHtmlTag(String s, int much) {
try {
Matcher m = null;
m = Pattern.compile("<([^>]*)>", Pattern.DOTALL).matcher(s);
while (m.find()) {
for (int i = 1; i <= m.groupCount(); i++) {
System.out.println("找到 = " + m.group());
s = s.replaceAll(m.group(), "");
}
}

