产生此问题的原因:
有两张表,table1和table2.产生此问题的原因就是table1里做了关联<one-to-one>或者<many-to-one unique="true">(特殊的多对一映射,实际就是一对一)来关联table2.当hibernate查找的时候,table2里的数据没有与table1相匹配的,这样就会报No row with the given identifier exists这个错.(一句话,就是数据的问题!)
假如说,table1里有自身的主键id1,还有table2的主键id2,这两个字段.
如果hibenrate设置的单项关联,即使table1中的id2为null值,table2中id2中有值,查询都不会出错.但是如果table1中的id2字段有值,但是这个值在table2中主键值里并没有,就会报上面的错!
如果hibernate是双向关联,那么table1中的id2为null值,但是table2中如果有值,就会报这个错.这种情况目前的解决办法就是改成单项关联,或者把不对应的数据改对!
这就是报这个错的原因了,知道原因了就相应的改就行了.或许还有些人迷惑hibernate关联都配好了,怎么会出现这样的错?其实这是编程的时候出现的问题,假如说我在添加信息的时候,页面传过来的struts的formbean到dao方法中需要封装成hibernate的po(就是hibenrate的bean),要是一个个po.get(form.set())实在太麻烦了,这样一般都会写个专门的方法来封装,遇到po.get(form.set())这种情况直接把struts的formbean对象传到此方法中封装就行了,假如我有个字段是创建人id,那么这个字段是永远不会改的,我在添加的时候还调用这个方法,这个专门封装的方法是有一些判断的,假如说我判断一下,如果遇到创建人id传过来为空值,我判断如果是空值,我把创建人id设为0,但是用户表中userid是主键从1开始自增的,那么这样数据就对应不上了,一查就会出这个错了.这个错在开发刚开始的时候经常发生,因为每个人的模块都是由相应的人独立开发完成以后再整合在一起的,每个人写单独那一块的时候往往会忽略这些,所以整合的时候这些问题往往就都一下子全冒出来了....整合很辛苦,tnnd!
hibernate的查询的比较
hibernate的查询有很多,Query,find,Criteria,get,load
有两张表,table1和table2.产生此问题的原因就是table1里做了关联<one-to-one>或者<many-to-one unique="true">(特殊的多对一映射,实际就是一对一)来关联table2.当hibernate查找的时候,table2里的数据没有与table1相匹配的,这样就会报No row with the given identifier exists这个错.(一句话,就是数据的问题!)
假如说,table1里有自身的主键id1,还有table2的主键id2,这两个字段.
如果hibenrate设置的单项关联,即使table1中的id2为null值,table2中id2中有值,查询都不会出错.但是如果table1中的id2字段有值,但是这个值在table2中主键值里并没有,就会报上面的错!
如果hibernate是双向关联,那么table1中的id2为null值,但是table2中如果有值,就会报这个错.这种情况目前的解决办法就是改成单项关联,或者把不对应的数据改对!
这就是报这个错的原因了,知道原因了就相应的改就行了.或许还有些人迷惑hibernate关联都配好了,怎么会出现这样的错?其实这是编程的时候出现的问题,假如说我在添加信息的时候,页面传过来的struts的formbean到dao方法中需要封装成hibernate的po(就是hibenrate的bean),要是一个个po.get(form.set())实在太麻烦了,这样一般都会写个专门的方法来封装,遇到po.get(form.set())这种情况直接把struts的formbean对象传到此方法中封装就行了,假如我有个字段是创建人id,那么这个字段是永远不会改的,我在添加的时候还调用这个方法,这个专门封装的方法是有一些判断的,假如说我判断一下,如果遇到创建人id传过来为空值,我判断如果是空值,我把创建人id设为0,但是用户表中userid是主键从1开始自增的,那么这样数据就对应不上了,一查就会出这个错了.这个错在开发刚开始的时候经常发生,因为每个人的模块都是由相应的人独立开发完成以后再整合在一起的,每个人写单独那一块的时候往往会忽略这些,所以整合的时候这些问题往往就都一下子全冒出来了....整合很辛苦,tnnd!
hibernate的查询的比较
hibernate的查询有很多,Query,find,Criteria,get,load
Tags: identifier
复制内容到剪贴板 程序代码
程序代码
程序代码<id name="oid" type="java.lang.Integer">
<column name="oid" />
<generator class="increment" />
</id>
<column name="oid" />
<generator class="increment" />
</id>
上述配置将使Hiberanate抛错:"当 IDENTITY_Insert 设置为 OFF 时,不能向表 '[USER]' 中的标识列插入显式值"
需要将该段设置为如下:
复制内容到剪贴板 程序代码
程序代码<id name="oid" type="java.lang.Integer">
<column name="oid" />
<generator class="identity" />
<column name="oid" />
<generator class="identity" />
08-01
15
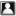 net.sf.hibernate.MappingException: Association references unmapped class: order.vo.KeysVO
net.sf.hibernate.MappingException: Association references unmapped class: order.vo.KeysVO
作者:Java伴侣 日期:2008-01-15
遇到该错误:
1.检查你的hibernate.cfg.xml文件中是否添加了
<mapping resource="order/vo/KeysWordsVO.hbm.xml"/>
2.检查你的hibernate.cfg.xml文件中的相关联的两个<mapping resource=""/>的顺序,可能有其中一个需要引用另一个,但是另一个却还没有编译
3.相应的 hbm.xml中的类名没有写对,注意跟实际类名包名的符合
Tags: MappingException
有些东西解释不明白,报错例子是这样的:
elite在NewsVO中为boolean型。
更改成:
复制内容到剪贴板 程序代码
程序代码 Query query=session.createQuery("FROM NewsVO as n where n.elite=:ELITE order by n.logtime desc");
query.setBoolean("ELITE", new Boolean(true));
query.setFirstResult(0);
query.setMaxResults(count);
query.setBoolean("ELITE", new Boolean(true));
query.setFirstResult(0);
query.setMaxResults(count);
elite在NewsVO中为boolean型。
更改成:
Tags: QueryException resolve property
在某些情况下,如果只希望检索出一个对象,可以先调用Query或Criteria接口的setMaxResult(1)方法,把最大检索数目设置为1;
接下来,调用uniqueResult()方法,该方法返回一个Object类型的对象:
如果明确知道查询结果(如where id=1),可以不调用setMaxResult(1)方法;
但是如果查询中有多个对象,但没有调用setMaxResult(1)方法,将会抛出NonUniqueResultException异常:
接下来,调用uniqueResult()方法,该方法返回一个Object类型的对象:
复制内容到剪贴板 程序代码
程序代码 Customer customer = (Customer)session.createQuery(from Customer c order c.name asc).setMaxResults(1).uniqueResult();
如果明确知道查询结果(如where id=1),可以不调用setMaxResult(1)方法;
但是如果查询中有多个对象,但没有调用setMaxResult(1)方法,将会抛出NonUniqueResultException异常:
复制内容到剪贴板 程序代码
程序代码[java] net.sf.hibernate.NoUniqueResultException:query did not return a unique result:99
Tags: 检索

