 上一篇
上一篇 下一篇
下一篇
08-12
19
百度sitemap深入研究
作者:Java伴侣 日期:2008-12-19


准确的说,叫它baidu sitemap不太准确,而且会有朋友问,百度有类似于google的xml格式sitemap吗?答案是有,但是它又不完全等同于sitemap。根据百度官方的描述,我们应该管它叫做《互联网新闻开放协议》。但是我还是喜欢叫它baidu sitemap,我觉得这个名称对站长来说更亲切一些:)
其实这个开放协议在06年4月初(或者更早几天)的时候,百度就已经公布了,我们看一下百度官方对这个开放协议所作的描述:
《互联网新闻开放协议》是百度新闻搜索制定的搜索引擎新闻源收录标准,网站可将发布的新闻内容制作成遵循此开放协议的XML格式的网页(独立于原有的新闻发布形式)供搜索引擎索引,将网站发布的新闻信息主动、及时地告知百度搜索引擎。
从官方的描述来看,这个开放协议针对的是新闻,似乎对我们没有什么价值,那么我们再假设一下,假如我们的网站通过互联网开放协议的审查,这样百度就会来抓取这个xml文档里的信息,那么即使我们的网站除了新闻之外还有很多别的内容,百度也会连这些内容一并抓取了。这样对百度及时更新索引网站最新内容是有很大的帮助的。
但是我发现众多的SEO们对百度的这个xml开放协议关注的人不多,甚至可以说几乎没有。可能还有不少SEO并不知道这个东西的存在,我就经常看见有朋友谈google sitemap,或者咨询相关问题。就是没有人讨论或者问这个“baidu sitemap”,可能的原因我猜是知者甚少。
当然,这个“baidu sitemap”对网站的要求更严格一些,如果你的网站是垃圾站,那么我建议不要去试了。因为这个xml的提交是需要百度进行审核的,所以还会有可能被K掉。这样对垃圾站来说似乎就得不偿失了。当然,如果你的网站足够好,并非垃圾站,那么可以去试一试。
不过,我在研究baidu sitemap的时候,发现一个比较严重的问题。其实这样的问题如果在国外是可以忽略的,但是在国内绝对有问题。众所周知,在中国,网站相互采集抄袭的情况空前严重,很多网站的内容都是抄来抄去。为什么baidu sitemap的使用会产生严重问题呢?我们来看一下baidu sitemap的xml格式代码。
XML标签说明: 其中带星号标记的为必选项,未带星号标记为可选项。
再放一张百度官方的截图:
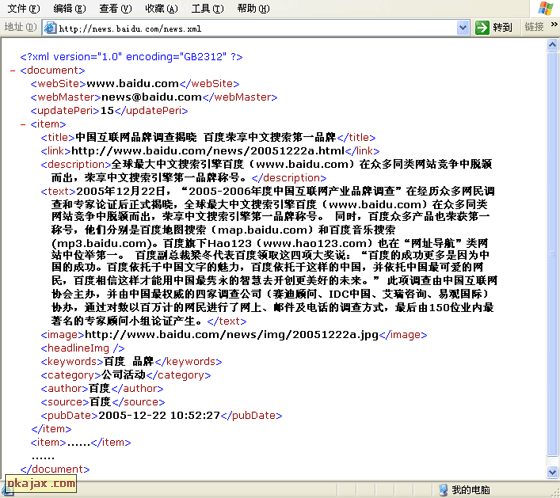
发现没有?这个xml文件里最大的一个问题就是我们需要把文章的全文放置在“<text>”中。有人会问,放全文有什么问题?结合这个xml格式,难道你没发现网页的全部关键内容都按照标准的格式展现出来了。产生的后果当然是:我要采集你的网站就跟玩似的,简直太容易了。
所以这篇文章我之所以取这么一个恐怖的名字是有原因的。是福是祸?福:当然是你的网站会得到百度的眷顾,不仅可能被列为新闻源,还会及时索引网站的最新网页。祸:当然就是一旦这个xml文件被发现,就面临被人轻松采集的危险。当然,垃圾站还有可能被百度K掉哦~~
是否应该使用baidu sitemap,相信大家心里应该有数,每个网站都有自己的算盘。
几个支持baidu sitemap功能的CMS,仅供参考:
动易CMS2006 SP4及以上
Supesite
*< document>——标记整个XML文件内容的开始和结束。
*< website>——站点地址。
*< webmaster>——负责人员的Email。当有必要时,我们通过这个地址与您联系。
*< updateperi>——更新周期,以分钟为单位。搜索引擎将遵照此周期访问该页面,使页面上的新闻更及时地出现在百度新闻中。
*< item>——标记每篇新闻信息的开始和结束。标记内为单篇新闻信息,不包括新闻专题。
*< title>——新闻标题。
*< link>——新闻url地址,与单篇新闻一一对应;若分页的新闻存在多个URL,相当于多篇新闻。
< description>——新闻内容简介。
*< text>——完整的新闻正文(仅包含正文文字,不包含HTML语言等其它字符)。此项的目的是使该篇新闻更多、更准地出现在搜索结果中。
*< image>——新闻正文内相关图片,采用绝对地址。若该篇新闻无相关图片,可以为空;若含有多张图片,请重复使用该标签。此项的目的是使该篇新闻的相关图片展现在搜索结果中。
< headlineimg>——为有可能成为头条的新闻制作的头条图,采用绝对地址。
< keywords>——反映新闻主题内容的一个或多个关键词,关键词之间以空格隔开。此项仅作为参考,检索结果不完全依赖于此标签中的内容。
< category>——新闻分类, 可以遵循网站自身的分类体系,最好采用一级分类。
< author>——新闻作者,可以为机构或个人 。
< source>——新闻来源,即原创媒体或其它机构 。
*< pubdate>——新闻发布时间,与该篇新闻HTML页面上的发布时间保持一致。请精确到分钟;若您网站的发布时间未记录小时分钟,提供年月日即可。
其实这个开放协议在06年4月初(或者更早几天)的时候,百度就已经公布了,我们看一下百度官方对这个开放协议所作的描述:
《互联网新闻开放协议》是百度新闻搜索制定的搜索引擎新闻源收录标准,网站可将发布的新闻内容制作成遵循此开放协议的XML格式的网页(独立于原有的新闻发布形式)供搜索引擎索引,将网站发布的新闻信息主动、及时地告知百度搜索引擎。
从官方的描述来看,这个开放协议针对的是新闻,似乎对我们没有什么价值,那么我们再假设一下,假如我们的网站通过互联网开放协议的审查,这样百度就会来抓取这个xml文档里的信息,那么即使我们的网站除了新闻之外还有很多别的内容,百度也会连这些内容一并抓取了。这样对百度及时更新索引网站最新内容是有很大的帮助的。
但是我发现众多的SEO们对百度的这个xml开放协议关注的人不多,甚至可以说几乎没有。可能还有不少SEO并不知道这个东西的存在,我就经常看见有朋友谈google sitemap,或者咨询相关问题。就是没有人讨论或者问这个“baidu sitemap”,可能的原因我猜是知者甚少。
当然,这个“baidu sitemap”对网站的要求更严格一些,如果你的网站是垃圾站,那么我建议不要去试了。因为这个xml的提交是需要百度进行审核的,所以还会有可能被K掉。这样对垃圾站来说似乎就得不偿失了。当然,如果你的网站足够好,并非垃圾站,那么可以去试一试。
不过,我在研究baidu sitemap的时候,发现一个比较严重的问题。其实这样的问题如果在国外是可以忽略的,但是在国内绝对有问题。众所周知,在中国,网站相互采集抄袭的情况空前严重,很多网站的内容都是抄来抄去。为什么baidu sitemap的使用会产生严重问题呢?我们来看一下baidu sitemap的xml格式代码。
XML标签说明: 其中带星号标记的为必选项,未带星号标记为可选项。
再放一张百度官方的截图:
发现没有?这个xml文件里最大的一个问题就是我们需要把文章的全文放置在“<text>”中。有人会问,放全文有什么问题?结合这个xml格式,难道你没发现网页的全部关键内容都按照标准的格式展现出来了。产生的后果当然是:我要采集你的网站就跟玩似的,简直太容易了。
所以这篇文章我之所以取这么一个恐怖的名字是有原因的。是福是祸?福:当然是你的网站会得到百度的眷顾,不仅可能被列为新闻源,还会及时索引网站的最新网页。祸:当然就是一旦这个xml文件被发现,就面临被人轻松采集的危险。当然,垃圾站还有可能被百度K掉哦~~
是否应该使用baidu sitemap,相信大家心里应该有数,每个网站都有自己的算盘。
几个支持baidu sitemap功能的CMS,仅供参考:
动易CMS2006 SP4及以上
Supesite
*< document>——标记整个XML文件内容的开始和结束。
*< website>——站点地址。
*< webmaster>——负责人员的Email。当有必要时,我们通过这个地址与您联系。
*< updateperi>——更新周期,以分钟为单位。搜索引擎将遵照此周期访问该页面,使页面上的新闻更及时地出现在百度新闻中。
*< item>——标记每篇新闻信息的开始和结束。标记内为单篇新闻信息,不包括新闻专题。
*< title>——新闻标题。
*< link>——新闻url地址,与单篇新闻一一对应;若分页的新闻存在多个URL,相当于多篇新闻。
< description>——新闻内容简介。
*< text>——完整的新闻正文(仅包含正文文字,不包含HTML语言等其它字符)。此项的目的是使该篇新闻更多、更准地出现在搜索结果中。
*< image>——新闻正文内相关图片,采用绝对地址。若该篇新闻无相关图片,可以为空;若含有多张图片,请重复使用该标签。此项的目的是使该篇新闻的相关图片展现在搜索结果中。
< headlineimg>——为有可能成为头条的新闻制作的头条图,采用绝对地址。
< keywords>——反映新闻主题内容的一个或多个关键词,关键词之间以空格隔开。此项仅作为参考,检索结果不完全依赖于此标签中的内容。
< category>——新闻分类, 可以遵循网站自身的分类体系,最好采用一级分类。
< author>——新闻作者,可以为机构或个人 。
< source>——新闻来源,即原创媒体或其它机构 。
*< pubdate>——新闻发布时间,与该篇新闻HTML页面上的发布时间保持一致。请精确到分钟;若您网站的发布时间未记录小时分钟,提供年月日即可。
 文章来自:
文章来自:  Tags:
Tags:  相关日志:
相关日志:
评论: 0 | 引用: 0 | 查看次数: 559
发表评论
