 上一篇
上一篇 下一篇
下一篇
07-03
19
人事部门管理系统(2)
作者:Java伴侣 日期:2007-03-19

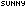

接着上次的继续说,上次说了讲的是“雇员添加”,程序步骤大致是:首页——遍历出部门列表——加入添加雇员表单——提交到存储过程——返回;但同时我忽略了一个前提:如果部门列表值为if(x.equest.("")||x==null)。那么应该给出一个error值,然后转发到“部门添加"页。但此种情况只会在程序第一次运行初始化的时候出现,而程序设计者在编写时就会在数据库中加入一些测试值,所以不会应该的使用情况。
添加部门表单页与上篇文章说的添加添加雇员程序思路大体一致,这里就不再赘述。下面我们看一下”管理部门员工 “功能的实现,主要思想:遍历和删除。如图:
数据库里写的东西很杂,呵呵。但我们主要关注的还是程序的实现!这个链接是link3.do,我们来看一下它在Stuts-config中的配置:
<action path="/link3" parameter="link3" type="companypj.Link3Action" validate="false" >
<forward name="link3_success" path="/link3.jsp">
</forward>
这里看到,没有作任何处理,它直接转到了Link3Action。那么我们看这个Atcion是怎么写的:
if (type.equals("link3")) {
log.info("return_link3..");
DepartmentBean depbean=new DepartmentBean(ds);
Collection DEPARTMENTS=depbean.getDepartments(); //取得所有部门信息
request.setAttribute(Constants.DEPARTMENTS_KEY,DEPARTMENTS);//request到下一个页面
return mapping.findForward(Constants_url.RETURN_LINK3_SUCCESS);//给sturts mapping传一个值
}
好了,转到getDepartments():
public Collection getDepartments()
{
log.info("提交所有部门数据集合");
return this.getDepartmentsHelper(Constants_sql.DEPARTMENT_ALL_SQL);
}
这里还是看不出什么,只是借助了Constants_sql类得到一个常量,上次我没有详细介绍过这里,这次我们来看看这个常量的定义:
public class Constants_sql {
public Constants_sql() {
}
public static final String DEPARTMENT_ADD_SQL=
"insert into department(name,description,leader,phone,address,starttime,info)values(?,?,?,?,?,?,?)";
public static final String DEPARTMENT_ALL_SQL="select * from department where name!='无部门' order by id desc"; //这里就是我们调用的常量
public static final String EMP_ADD_SQL=
"insert into employee (name,sex,age,salary,department,marriage,address,phone,resume) values(?,?,?,?,?,?,?,?,?)";
public static final String EMP_ALL_SQL="select * from employee where department!='无部门' order by id desc";
public static final String EMP_TEMP_ALL_SQL="select * from employee where department='无部门' order by id desc";
//public static final String
}
DEPARTMENT_ALL_SQL:把table department中所有name非'无部门'的记录取出,并降序排列。
回到getDepartments()方法,这个方法就是为了更好的解耦合,之后它再调用getDepartmentsHelper()方法,并且传入了一个String DEPARTMENT_ALL_SQL;getDepartments()方法:
private Collection getDepartmentsHelper(String sql) //遍历集合 帮助方法
{
Collection list=new ArrayList();
try {
Connection conn=ds.getConnection();
Statement stmt=conn.createStatement();
ResultSet rs=stmt.executeQuery(sql);
while(rs.next())
{
DepartmentVO departmentvo=new DepartmentVO();
// log.info("取部门数据开始");
departmentvo.setId(rs.getInt("id"));
departmentvo.setName(rs.getString("name"));
departmentvo.setDescription(rs.getString("description"));
log.info(rs.getString("description"));
departmentvo.setLeader(rs.getString("leader"));
departmentvo.setPhone(rs.getString("phone"));
departmentvo.setAddress(rs.getString("address"));
departmentvo.setStarttime(rs.getString("starttime"));
departmentvo.setInfo(rs.getString("info"));
list.add(departmentvo);
// log.info("取部门数据结束");
}
conn.close();
stmt.close();
rs.close();
} catch (SQLException ex) {
ex.getMessage();
}
return list;
}
返回list,而list里面就是我们要的部门集合;拿着它返回页面遍历即可;就是上面的这两句:
request.setAttribute(Constants.DEPARTMENTS_KEY,DEPARTMENTS);//request到下一个页面
return mapping.findForward(Constants_url.RETURN_LINK3_SUCCESS);//给sturts mapping传一个值
返回的时候依旧是先调用一个常量类(我发现我那时写程序真够BT的了,BT..病态)
public static final String RETURN_LINK3_SUCCESS="link3_success";
把link3_success信息传给strut_config来处理,Struts这句话是用来接收它的:
<forward name="link3_success" path="/link3.jsp">
好了,现在我们来看看link3.jsp的组成,Tiles配置:
<definition extends="layout-definition" name="link3-definition">
<put name="content" value="return/departmentManage.jsp"></put>
</definition>
从这里看到,实际把权的是departmentManage.jsp页。看看它的信息:
<table cellpadding="0" cellspacing="5" width="100%" >
<tr>
<td width="14%"><bean:message key="lable.dept.row.id"/></td>
<td width="14%"><bean:message key="lable.dept.row.name"/></td>
<td width="14%"><bean:message key="lable.dept.row.leader"/></td>
<td width="14%"><bean:message key="lable.dept.row.add.emp"/></td>
<td width="14%"><bean:message key="lable.dept.row.delete.emp"/></td>
</tr>
<tr>
<td width="100%" colspan="5">
<page:pager dz="5">
<%int i=1; %>
<logic:iterate id="departments" name="DEPARTMENTS" type="companypj.DepartmentVO">
<table border="1" cellpadding="0" cellspacing="1" style="border-collapse: collapse" width="100%" >
<page:item nr="<%=i++%>">
<tr>
<td width="14%"><bean:write name="departments" property="id"/></td>
<td width="14%"><bean:write name="departments" property="name"/></td>
<td width="14%"><bean:write name="departments" property="leader"/></td>
<td width="14%"><html:link page="/link3_add.do">
<bean:message key="lable.dept.add.emp"/>
</html:link></td>
<td width="14%">
<bean:define id="dep_id" name="departments" property="id">
</bean:define>
<html:link page="/link3_delete.do" paramId="dep_id" paramName="dep_id">
<bean:message key="lable.dept.delete.emp"/>
</html:link>
</td>
</tr>
</page:item>
</table>
<br>
</logic:iterate>
</page:pager>
</td>
</tr>
</table>
<center>
<p>
<page:bt/>
<%@taglib uri="/WEB-INF/jpager.tld" prefix="page"%>这里的pager标签是分页用的插件,我们先不去考虑它,在最后的时候我再讲关于这个项目外的一些扩展功能。
从上面jsp我们可以看到logic遍历,还有一些很重要的东西,一个是添加员工到部门的功能,主要我的话,这个和添加新员工有一定的区别,是把一些'‘无部门’的员工加入到该部门。为什么会出现"无部门"员工呢?出于种种原因的考虑,主要是因为员工档案的重要性,所以这个项目的删除员工并非是作delete操作,还是update,把某员工的部门属性到上标记。也考虑到新员工不一定会直接配分到某部门,可能再过一段时间。再来还有一个逻辑性的问题,在删除一个部门的时候,员工必须先转移到别的部门,这么以来。删除员工的操作势必不可行。
如图:
在这里,我们就可以看到所有”无部门“人员列表。
jsp页面,我全部是用<bean:message标签来做的,lable.dept.add.emp对应资源文件中的uc码,也就是”添加“。link3_add.do,那我们跟着这条线走吧。。
Link3Action:
if(type.equals("link3_add"))
{
log.info("link3_temp..");
EmployeeBean empbean=new EmployeeBean(ds);
Collection EMPSTEMP=empbean.getTempEmps(); //这里就看到了取得TEMP员工的方法
request.setAttribute(Constants.EMPS_TEMP_KEY,EMPSTEMP);
return mapping.findForward(Constants_url.RETURN_LINK3_ADD_SUCCESS);
}
看一下getTempEmps()方法,下面的一系列程序是在做找到所有没有部门的员工:
public Collection getTempEmps() { //获得所有无部门的员工
return this.getEmployeesHelper(Constants_sql.EMP_TEMP_ALL_SQL);
}
这里值得注意的是SQL的写法EMP_TEMP_ALL_SQL:
接着看实质的方法getEmployeesHelper:
private Collection getEmployeesHelper(String sql) {
Collection list = new ArrayList();
try {
Connection conn = ds.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
EmployeeVO employeeVO = new EmployeeVO();
log.info("取人员信息开始");
employeeVO.setId(rs.getInt("id"));
employeeVO.setName(rs.getString("name"));
employeeVO.setSex(rs.getString("sex"));
employeeVO.setAge(rs.getInt("age"));
employeeVO.setSalary(rs.getString("salary"));
employeeVO.setDepartment(rs.getString("department"));
employeeVO.setMarriage(rs.getString("marriage"));
employeeVO.setAddress(rs.getString("address"));
employeeVO.setPhone(rs.getString("phone"));
employeeVO.setResume(rs.getString("resume"));
list.add(employeeVO);
log.info("取人员信息结束");
}
conn.close();
stmt.close();
rs.close();
} catch (SQLException ex) {
}
return list;
}
OK,已经取得list集合,返回,并遍历显示到页面即可!
下面这个是删除部门中员工的链接:
<bean:define id="dep_id" name="departments" property="id">
</bean:define>
<html:link page="/link3_delete.do" paramId="dep_id" paramName="dep_id">
<bean:message key="lable.dept.delete.emp"/>
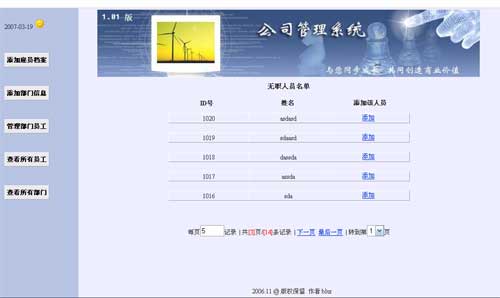
先要确定某一部门的id,得到id后,相应的去数据库中找到集合。如图:
在Action中的取得方法:
if(type.equals("link3_delete"))
{
log.info("delete ready..");
EmployeeBean empbean=new EmployeeBean(ds);
Collection DEPTEMPS=empbean.getDepartemtDemployees(request.getParameter("dep_id"));
request.getSession().setAttribute("DEP_ID",request.getParameter("dep_id"));
//保存部门ID号,以便删除之后可以返回页
request.setAttribute(Constants.DEPT_EMPS_KEY,DEPTEMPS);
return mapping.findForward(Constants_url.RETURN_LINK3_Delete_READY);
}
最先调用的方法getDepartemtDemployees():
public Collection getDepartemtDemployees(String dep_id) { //指定部门中的员工
log.info("该部门是:" + dep_id);
String sql_dep =
"select * from employee where department=(select name from department where id=" +
dep_id + ")";
log.info(sql_dep);
return this.getEmployeesHelper(sql_dep);
}
这里的SQL挺有意思,带有子查询,当然写法很多,不止这一种。
接着转入帮助方法getEmployeesHelper();帮助方法都是一样,上面已经写出,不再重复。不过写到现在,可以明显看出,实际操作的方法并不多,都是经过bean前的一个方法中转——解耦。
好了,接下来说一下删除部门中的某一个成员:
上面说到把某部门的所有成员遍历到页面显示,返回的集合是:
下面到对应的jsp页面来看下:
<logic:iterate id="dept_emps" name="DEPTEMPS">
<page:item nr="<%=i++%>">
<table border="0" cellpadding="0" cellspacing="0" style="border-collapse: collapse" width="100%">
<tr>
<td width="33%"><bean:write name="dept_emps" property="id"/>��</td>
<td width="33%"><bean:write name="dept_emps" property="name"/></td>
<td width="34%">
<bean:define id="ID" name="dept_emps" property="id"/>
<html:link page="/link3_deleted.do" paramId="id" paramName="ID">
<bean:message key="lable.delete.emp.this"/>
</html:link>
</td>
</tr>
</table>
<br>
</page:item>
</logic:iterate>
这里可以看出,name已经接收了返回的集合,并做了遍历,而删除按钮lable.delete.emp.this做了一个超链,带有传参:传的是员工的id号,我们下面看看后台它的运作过程:
if(type.equals("link3_deleted"))
{
EmployeeBean empbean=new EmployeeBean(ds);
empbean.deleteEmployee(request.getParameter("id"));//删除某个员工
Collection DEPTEMPS=empbean.getDepartemtDemployees(String.valueOf(request.getSession().getAttribute("DEP_ID")));//再取部门人员
log.info("转发回页面");
request.setAttribute(Constants.DEPT_EMPS_KEY,DEPTEMPS);
return mapping.findForward(Constants_url.RETURN_LINK3_DeleteD_SUCCESS);
}
return null;
}
中间层调用了两个方法,一个是删除员工,为了删除后保持页面的一致性,再重新遍历一下该部门的所有员工:
而部门ID已经存入了session中,为DEP_ID。先看deleteEmployee():
public void deleteEmployee(String id) {
try {
log.info("1");
Connection conn = ds.getConnection();
Statement stmt = conn.createStatement();
String sql_update = "update employee set department='无部门' where id=" +
id + "";
log.info(sql_update);
stmt.executeUpdate(sql_update);
log.info("2");
conn.close();
stmt.close();
} catch (SQLException ex) {
}
删除方法够简单的,传进id,update把dep字段改成"无部门"就OK。
重新遍历出员工和上一个超级链接做的是一样的工作,然后还是返回刚才的页面,可以看见新的数据。
添加部门表单页与上篇文章说的添加添加雇员程序思路大体一致,这里就不再赘述。下面我们看一下”管理部门员工 “功能的实现,主要思想:遍历和删除。如图:
数据库里写的东西很杂,呵呵。但我们主要关注的还是程序的实现!这个链接是link3.do,我们来看一下它在Stuts-config中的配置:
复制内容到剪贴板 程序代码
程序代码
程序代码<action path="/link3" parameter="link3" type="companypj.Link3Action" validate="false" >
<forward name="link3_success" path="/link3.jsp">
</forward>
这里看到,没有作任何处理,它直接转到了Link3Action。那么我们看这个Atcion是怎么写的:
复制内容到剪贴板 程序代码
程序代码if (type.equals("link3")) {
log.info("return_link3..");
DepartmentBean depbean=new DepartmentBean(ds);
Collection DEPARTMENTS=depbean.getDepartments(); //取得所有部门信息
request.setAttribute(Constants.DEPARTMENTS_KEY,DEPARTMENTS);//request到下一个页面
return mapping.findForward(Constants_url.RETURN_LINK3_SUCCESS);//给sturts mapping传一个值
}
好了,转到getDepartments():
复制内容到剪贴板 程序代码
程序代码public Collection getDepartments()
{
log.info("提交所有部门数据集合");
return this.getDepartmentsHelper(Constants_sql.DEPARTMENT_ALL_SQL);
}
这里还是看不出什么,只是借助了Constants_sql类得到一个常量,上次我没有详细介绍过这里,这次我们来看看这个常量的定义:
复制内容到剪贴板 程序代码
程序代码public class Constants_sql {
public Constants_sql() {
}
public static final String DEPARTMENT_ADD_SQL=
"insert into department(name,description,leader,phone,address,starttime,info)values(?,?,?,?,?,?,?)";
public static final String DEPARTMENT_ALL_SQL="select * from department where name!='无部门' order by id desc"; //这里就是我们调用的常量
public static final String EMP_ADD_SQL=
"insert into employee (name,sex,age,salary,department,marriage,address,phone,resume) values(?,?,?,?,?,?,?,?,?)";
public static final String EMP_ALL_SQL="select * from employee where department!='无部门' order by id desc";
public static final String EMP_TEMP_ALL_SQL="select * from employee where department='无部门' order by id desc";
//public static final String
}
DEPARTMENT_ALL_SQL:把table department中所有name非'无部门'的记录取出,并降序排列。
回到getDepartments()方法,这个方法就是为了更好的解耦合,之后它再调用getDepartmentsHelper()方法,并且传入了一个String DEPARTMENT_ALL_SQL;getDepartments()方法:
复制内容到剪贴板 程序代码
程序代码private Collection getDepartmentsHelper(String sql) //遍历集合 帮助方法
{
Collection list=new ArrayList();
try {
Connection conn=ds.getConnection();
Statement stmt=conn.createStatement();
ResultSet rs=stmt.executeQuery(sql);
while(rs.next())
{
DepartmentVO departmentvo=new DepartmentVO();
// log.info("取部门数据开始");
departmentvo.setId(rs.getInt("id"));
departmentvo.setName(rs.getString("name"));
departmentvo.setDescription(rs.getString("description"));
log.info(rs.getString("description"));
departmentvo.setLeader(rs.getString("leader"));
departmentvo.setPhone(rs.getString("phone"));
departmentvo.setAddress(rs.getString("address"));
departmentvo.setStarttime(rs.getString("starttime"));
departmentvo.setInfo(rs.getString("info"));
list.add(departmentvo);
// log.info("取部门数据结束");
}
conn.close();
stmt.close();
rs.close();
} catch (SQLException ex) {
ex.getMessage();
}
return list;
}
返回list,而list里面就是我们要的部门集合;拿着它返回页面遍历即可;就是上面的这两句:
复制内容到剪贴板 程序代码
程序代码request.setAttribute(Constants.DEPARTMENTS_KEY,DEPARTMENTS);//request到下一个页面
return mapping.findForward(Constants_url.RETURN_LINK3_SUCCESS);//给sturts mapping传一个值
返回的时候依旧是先调用一个常量类(我发现我那时写程序真够BT的了,BT..病态)
复制内容到剪贴板 程序代码
程序代码public static final String RETURN_LINK3_SUCCESS="link3_success";
把link3_success信息传给strut_config来处理,Struts这句话是用来接收它的:
复制内容到剪贴板 程序代码
程序代码<forward name="link3_success" path="/link3.jsp">
好了,现在我们来看看link3.jsp的组成,Tiles配置:
<definition extends="layout-definition" name="link3-definition">
<put name="content" value="return/departmentManage.jsp"></put>
</definition>
从这里看到,实际把权的是departmentManage.jsp页。看看它的信息:
复制内容到剪贴板 程序代码
程序代码<table cellpadding="0" cellspacing="5" width="100%" >
<tr>
<td width="14%"><bean:message key="lable.dept.row.id"/></td>
<td width="14%"><bean:message key="lable.dept.row.name"/></td>
<td width="14%"><bean:message key="lable.dept.row.leader"/></td>
<td width="14%"><bean:message key="lable.dept.row.add.emp"/></td>
<td width="14%"><bean:message key="lable.dept.row.delete.emp"/></td>
</tr>
<tr>
<td width="100%" colspan="5">
<page:pager dz="5">
<%int i=1; %>
<logic:iterate id="departments" name="DEPARTMENTS" type="companypj.DepartmentVO">
<table border="1" cellpadding="0" cellspacing="1" style="border-collapse: collapse" width="100%" >
<page:item nr="<%=i++%>">
<tr>
<td width="14%"><bean:write name="departments" property="id"/></td>
<td width="14%"><bean:write name="departments" property="name"/></td>
<td width="14%"><bean:write name="departments" property="leader"/></td>
<td width="14%"><html:link page="/link3_add.do">
<bean:message key="lable.dept.add.emp"/>
</html:link></td>
<td width="14%">
<bean:define id="dep_id" name="departments" property="id">
</bean:define>
<html:link page="/link3_delete.do" paramId="dep_id" paramName="dep_id">
<bean:message key="lable.dept.delete.emp"/>
</html:link>
</td>
</tr>
</page:item>
</table>
<br>
</logic:iterate>
</page:pager>
</td>
</tr>
</table>
<center>
<p>
<page:bt/>
<%@taglib uri="/WEB-INF/jpager.tld" prefix="page"%>这里的pager标签是分页用的插件,我们先不去考虑它,在最后的时候我再讲关于这个项目外的一些扩展功能。
从上面jsp我们可以看到logic遍历,还有一些很重要的东西,一个是添加员工到部门的功能,主要我的话,这个和添加新员工有一定的区别,是把一些'‘无部门’的员工加入到该部门。为什么会出现"无部门"员工呢?出于种种原因的考虑,主要是因为员工档案的重要性,所以这个项目的删除员工并非是作delete操作,还是update,把某员工的部门属性到上标记。也考虑到新员工不一定会直接配分到某部门,可能再过一段时间。再来还有一个逻辑性的问题,在删除一个部门的时候,员工必须先转移到别的部门,这么以来。删除员工的操作势必不可行。
复制内容到剪贴板 程序代码
程序代码<html:link page="/link3_add.do">
<bean:message key="lable.dept.add.emp"/>
</html:link>
<bean:message key="lable.dept.add.emp"/>
</html:link>
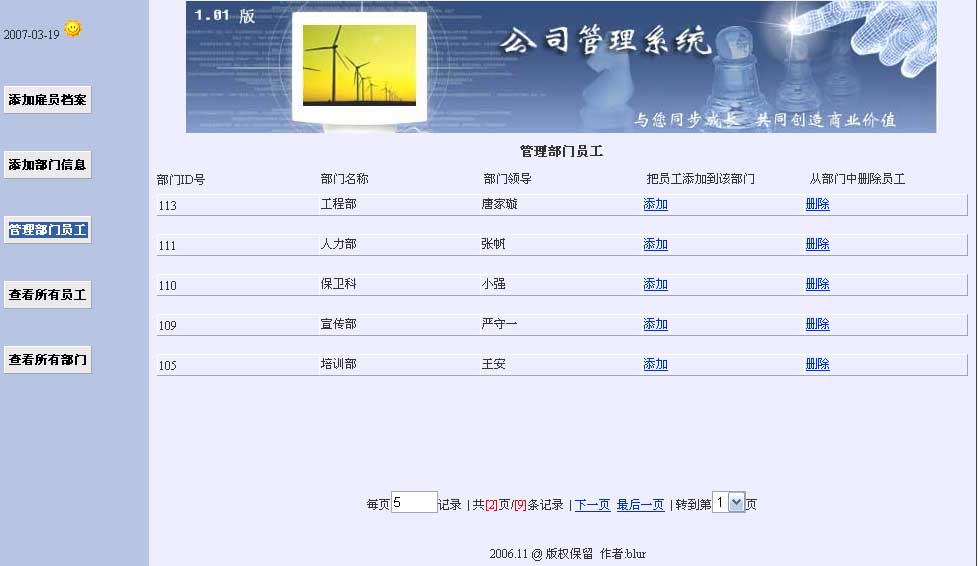
如图:
在这里,我们就可以看到所有”无部门“人员列表。
jsp页面,我全部是用<bean:message标签来做的,lable.dept.add.emp对应资源文件中的uc码,也就是”添加“。link3_add.do,那我们跟着这条线走吧。。
复制内容到剪贴板 程序代码
程序代码<action path="/link3_add" parameter="link3_add" type="companypj.Link3Action" validate="false">
Link3Action:
复制内容到剪贴板 程序代码
程序代码if(type.equals("link3_add"))
{
log.info("link3_temp..");
EmployeeBean empbean=new EmployeeBean(ds);
Collection EMPSTEMP=empbean.getTempEmps(); //这里就看到了取得TEMP员工的方法
request.setAttribute(Constants.EMPS_TEMP_KEY,EMPSTEMP);
return mapping.findForward(Constants_url.RETURN_LINK3_ADD_SUCCESS);
}
看一下getTempEmps()方法,下面的一系列程序是在做找到所有没有部门的员工:
复制内容到剪贴板 程序代码
程序代码public Collection getTempEmps() { //获得所有无部门的员工
return this.getEmployeesHelper(Constants_sql.EMP_TEMP_ALL_SQL);
}
这里值得注意的是SQL的写法EMP_TEMP_ALL_SQL:
复制内容到剪贴板 程序代码
程序代码public static final String EMP_TEMP_ALL_SQL="select * from employee where department='无部门' order by id desc";
接着看实质的方法getEmployeesHelper:
复制内容到剪贴板 程序代码
程序代码private Collection getEmployeesHelper(String sql) {
Collection list = new ArrayList();
try {
Connection conn = ds.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
EmployeeVO employeeVO = new EmployeeVO();
log.info("取人员信息开始");
employeeVO.setId(rs.getInt("id"));
employeeVO.setName(rs.getString("name"));
employeeVO.setSex(rs.getString("sex"));
employeeVO.setAge(rs.getInt("age"));
employeeVO.setSalary(rs.getString("salary"));
employeeVO.setDepartment(rs.getString("department"));
employeeVO.setMarriage(rs.getString("marriage"));
employeeVO.setAddress(rs.getString("address"));
employeeVO.setPhone(rs.getString("phone"));
employeeVO.setResume(rs.getString("resume"));
list.add(employeeVO);
log.info("取人员信息结束");
}
conn.close();
stmt.close();
rs.close();
} catch (SQLException ex) {
}
return list;
}
OK,已经取得list集合,返回,并遍历显示到页面即可!
下面这个是删除部门中员工的链接:
复制内容到剪贴板 程序代码
程序代码<bean:define id="dep_id" name="departments" property="id">
</bean:define>
<html:link page="/link3_delete.do" paramId="dep_id" paramName="dep_id">
<bean:message key="lable.dept.delete.emp"/>
先要确定某一部门的id,得到id后,相应的去数据库中找到集合。如图:
在Action中的取得方法:
复制内容到剪贴板 程序代码
程序代码if(type.equals("link3_delete"))
{
log.info("delete ready..");
EmployeeBean empbean=new EmployeeBean(ds);
Collection DEPTEMPS=empbean.getDepartemtDemployees(request.getParameter("dep_id"));
request.getSession().setAttribute("DEP_ID",request.getParameter("dep_id"));
//保存部门ID号,以便删除之后可以返回页
request.setAttribute(Constants.DEPT_EMPS_KEY,DEPTEMPS);
return mapping.findForward(Constants_url.RETURN_LINK3_Delete_READY);
}
最先调用的方法getDepartemtDemployees():
复制内容到剪贴板 程序代码
程序代码public Collection getDepartemtDemployees(String dep_id) { //指定部门中的员工
log.info("该部门是:" + dep_id);
String sql_dep =
"select * from employee where department=(select name from department where id=" +
dep_id + ")";
log.info(sql_dep);
return this.getEmployeesHelper(sql_dep);
}
这里的SQL挺有意思,带有子查询,当然写法很多,不止这一种。
接着转入帮助方法getEmployeesHelper();帮助方法都是一样,上面已经写出,不再重复。不过写到现在,可以明显看出,实际操作的方法并不多,都是经过bean前的一个方法中转——解耦。
好了,接下来说一下删除部门中的某一个成员:
上面说到把某部门的所有成员遍历到页面显示,返回的集合是:
复制内容到剪贴板 程序代码
程序代码public static final String DEPT_EMPS_KEY="DEPTEMPS";
下面到对应的jsp页面来看下:
复制内容到剪贴板 程序代码
程序代码<logic:iterate id="dept_emps" name="DEPTEMPS">
<page:item nr="<%=i++%>">
<table border="0" cellpadding="0" cellspacing="0" style="border-collapse: collapse" width="100%">
<tr>
<td width="33%"><bean:write name="dept_emps" property="id"/>��</td>
<td width="33%"><bean:write name="dept_emps" property="name"/></td>
<td width="34%">
<bean:define id="ID" name="dept_emps" property="id"/>
<html:link page="/link3_deleted.do" paramId="id" paramName="ID">
<bean:message key="lable.delete.emp.this"/>
</html:link>
</td>
</tr>
</table>
<br>
</page:item>
</logic:iterate>
这里可以看出,name已经接收了返回的集合,并做了遍历,而删除按钮lable.delete.emp.this做了一个超链,带有传参:传的是员工的id号,我们下面看看后台它的运作过程:
复制内容到剪贴板 程序代码
程序代码if(type.equals("link3_deleted"))
{
EmployeeBean empbean=new EmployeeBean(ds);
empbean.deleteEmployee(request.getParameter("id"));//删除某个员工
Collection DEPTEMPS=empbean.getDepartemtDemployees(String.valueOf(request.getSession().getAttribute("DEP_ID")));//再取部门人员
log.info("转发回页面");
request.setAttribute(Constants.DEPT_EMPS_KEY,DEPTEMPS);
return mapping.findForward(Constants_url.RETURN_LINK3_DeleteD_SUCCESS);
}
return null;
}
中间层调用了两个方法,一个是删除员工,为了删除后保持页面的一致性,再重新遍历一下该部门的所有员工:
而部门ID已经存入了session中,为DEP_ID。先看deleteEmployee():
复制内容到剪贴板 程序代码
程序代码public void deleteEmployee(String id) {
try {
log.info("1");
Connection conn = ds.getConnection();
Statement stmt = conn.createStatement();
String sql_update = "update employee set department='无部门' where id=" +
id + "";
log.info(sql_update);
stmt.executeUpdate(sql_update);
log.info("2");
conn.close();
stmt.close();
} catch (SQLException ex) {
}
删除方法够简单的,传进id,update把dep字段改成"无部门"就OK。
重新遍历出员工和上一个超级链接做的是一样的工作,然后还是返回刚才的页面,可以看见新的数据。
 文章来自:
文章来自:  Tags:
Tags:  相关日志:
相关日志:
评论: 0 | 引用: 0 | 查看次数: 964
发表评论
