08-01
18
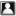 failed to lazily initialize a collection of role: no session or session was closed
failed to lazily initialize a collection of role: no session or session was closed
作者:Java伴侣 日期:2008-01-18
用jsp研究了下,发现原来小偷可以如此简单。。。。差不多就是读取文件,只是变为了远程而已
代码如下:
代码如下:
复制内容到剪贴板 程序代码
程序代码
程序代码<%@ page language="java" pageEncoding="UTF-8"%>
<%@ page import="java.io.*,java.net.URL"%>
<%
URL url = new URL("http://www.itpub.net");//建立URL对象,并实例化为url,获得要抓取的网页地址
BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream(),"GB2312"));//建立BufferedReader对象,并实例化为reader,这里的GB2312是要抓取的网页编码格式
while(reader.ready())
<%@ page import="java.io.*,java.net.URL"%>
<%
URL url = new URL("http://www.itpub.net");//建立URL对象,并实例化为url,获得要抓取的网页地址
BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream(),"GB2312"));//建立BufferedReader对象,并实例化为reader,这里的GB2312是要抓取的网页编码格式
while(reader.ready())
最近网上流行着一些采集程序,更多人拿着这些东西在网上叫卖,很多不太懂的人看着那些程序眼羡,其实如果你懂一些ASP,了解自动采集程序的原理后,你会感觉实现自动化也是那么的简单.
原理及优点:通过XML中的XMLHTTP组件调用其它网站上的网页,然后批量截取或替换原有的信息使其转化成变量后再一一储存到数据库中。其主要的优点便是无需再手工添加大量的信息了,可以指定对某一个站信息的截取进行批量录入,达到省时省力的目的。与其单纯的ASP小偷程序不同的是:它已经不再依赖其目标网站。
简单事例:
原理及优点:通过XML中的XMLHTTP组件调用其它网站上的网页,然后批量截取或替换原有的信息使其转化成变量后再一一储存到数据库中。其主要的优点便是无需再手工添加大量的信息了,可以指定对某一个站信息的截取进行批量录入,达到省时省力的目的。与其单纯的ASP小偷程序不同的是:它已经不再依赖其目标网站。
简单事例:
复制内容到剪贴板 程序代码
程序代码 1<%
2'声明取得目标信息的函数,通过XML组件进行实现。
3Function GetURL(url)
4Set Retrieval = CreateObject("Microsoft.XMLHTTP")
5With Retrieval
6.Open "GET", url, False
2'声明取得目标信息的函数,通过XML组件进行实现。
3Function GetURL(url)
4Set Retrieval = CreateObject("Microsoft.XMLHTTP")
5With Retrieval
6.Open "GET", url, False
Tags: 自动采集

